NTTドコモ サービスイノベーション部の中村圭佑です。普段の業務では画像認識に関する研究開発を行っています。今回は話題となっている画像生成について、社内勉強会にて発表を行いましたので、発表スライドとともにご紹介できればと思います。詳しくは埋め込みのslideshareからご覧になれます。 勉強会ではオフライン・オンライン共に多くの方々にご来場いただき、昨今の生成系AIに対する関心の高さを実感しました。特にユースケースや権利問題については多くのご質問を頂き、ビジネスでの利用に興味がある方が多い印象を受けました。生成系AIは便利である反面さまざまなリスクを抱えているため、R&Dでこのような勉強会を引き続き出来れば良いなと思いました。
発表スライドはこちら今回は大きく分けて4つの内容で話しました。- Diffusionへの歩み- Diffusionの広がりとユースケース - Diffusionの罠- まとめ
Diffusionへの歩み(スライドp.7〜)ここでは最初に機械学習初学者でも理解しやすいよう、VAEやGANから現在主流となっているDiffusionモデルへの変遷について紹介しています。勉強会では従来の画像生成手法であるGANと異なり、ノイズ画像から目的の画像を生成する過程を学習するのではなく、画像にノイズを時間経過ごとに入れていき、その逆変換を学習していることを説明しました.Stable diffusion(Latent diffusion)のモデルを見ると実空間の画像を潜在(低次元)空間に移すVAEとテキストエンコーダとしての役割を果たしているCLIP、そしてデノイジング部分で構成されていることがわかります。今までの画像生成モデルの良いところが取り入れられており、text2imageモデルの集大成だなと考えています。大きく分けて3つの内容を紹介しています。- VAEからStable diffusionに⾄るまでの画像⽣成AIの歴史- DDPM(Denoising diffusion probabilistic models)と拡散モデルの基礎- Stable diffusionのアーキテクチャについて(VAE, U-net, CLIPなどを紹介)
この章では画像生成モデルで出来ることや実際のユースケース、公開されているモデルについて紹介しています。ビジネス面でのユースケースは現状少ないなと感じていますが、広告生成・デザイン支援・動画像編集などの目的で着々と導入が進んでいます。目的の画像を生成するためのガイダンス手法やFinetuning手法も続々と研究が進められています。特にLoRA(Low-Rank Adaption)はStable diffusionのFinetuning手法としてはメインストリームになっています。元のパラメータを弄ることなくAttention Layerに追加した差分のパラメータを学習するため、従来のモデル全体をTuningするDreambooth等の手法と比べて非常に高速で計算量が少なくなっています。ここでは5つの内容を話しました。- Stable diffusionで出来ること。txt2img、img2img、inpainting、outpaintingについて- モデル公開サイトの紹介- 有名どころの事前学習済みモデル紹介- ガイダンス手法やLoRA等のfinetuning手法について- ビジネスでのユースケース

ここではサービスでの商用利用などで避けては通れないセキュリティ、著作権、肖像権、倫理問題について触れています。多くの権利問題があり、法的な整理がなされていない部分も多いため画像生成AI関連のサービスを立ち上げるのは中々難しいことが分かると思います。モデル自体にセキュリティホールがある場合があり、安全に使うには「.safetensors」形式を使うなど、何らかの対処が必要だと考えています。
画像生成サービスの利用条件モデルの安全性・正当性について著作権について肖像権について学習データの倫理問題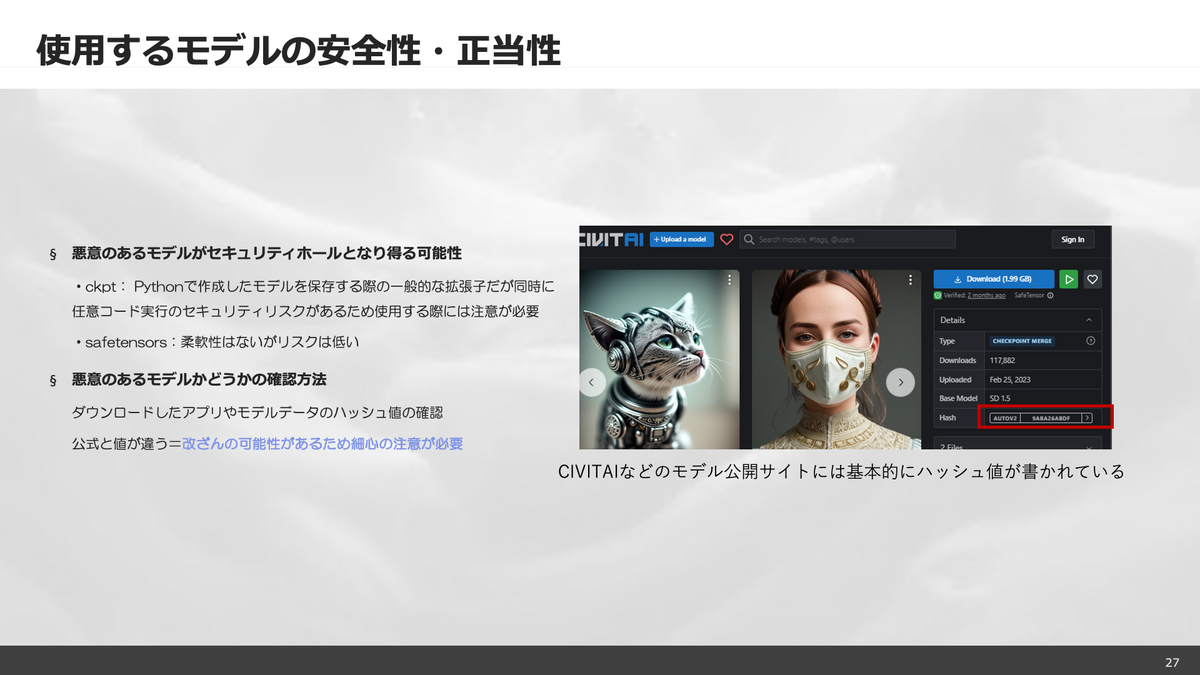
 まとめ(スライドp.36〜)
まとめ(スライドp.36〜)勉強会では以下の疑問に回答できるような発表を心がけました。
dcm_keisuke_nakamura 2023-10-06 09:00

NTTドコモ R&Dの技術ブログです。 AI、クラウド、IoT、無線通信などの幅広い技術情報やイベント情報について紹介します。 プライバシーポリシー、Google Analyticsの利用、商標、推奨環境などについては、Aboutページをご確認ください。
NTTドコモでは新卒採用、キャリア採用を積極的に実施しております。新卒採用
キャリア採用
 2024-11-07データのつながりを解き明かす!Graph Embeddingの考え方と適用例の紹介 AI・機械学習 python データ分析
2024-11-07データのつながりを解き明かす!Graph Embeddingの考え方と適用例の紹介 AI・機械学習 python データ分析  2024-11-06「引用論文の影響度合いを予測せよ」:データ分析コンペKDDCUP2024 OAG-PST 8位入賞解法紹介 論文・研究紹介 データ分析 AI・機械学習
2024-11-06「引用論文の影響度合いを予測せよ」:データ分析コンペKDDCUP2024 OAG-PST 8位入賞解法紹介 論文・研究紹介 データ分析 AI・機械学習  2024-10-17データ分析コンペKDDCUP 2024 OAG-AQA 6位入賞解法の紹介 論文・研究紹介 データ分析 AI・機械学習
2024-10-17データ分析コンペKDDCUP 2024 OAG-AQA 6位入賞解法の紹介 論文・研究紹介 データ分析 AI・機械学習